Hazelcast(概述)
简介
开源中国的简介:
Hazelcast是一个高度可扩展的数据分发和集群平台。特性包括:
- 提供java.util.{Queue, Set, List, Map}分布式实现。
- 提供java.util.concurrency.locks.Lock分布式实现。
- 提供java.util.concurrent.ExecutorService分布式实现。
- 提供用于一对多关系的分布式MultiMap。
- 提供用于发布/订阅的分布式Topic(主题)。
- 通过JCA与J2EE容器集成和事务支持。
- 提供用于安全集群的Socket层加密。
- 支持同步和异步持久化。
- 为Hibernate提供二级缓存Provider 。
- 通过JMX监控和管理集群。
- 支持动态HTTP Session集群。
- 利用备份实现动态分割。
- 支持动态故障恢复。
简介是美好的,现实是坑爹的。
优点
先说下优点吧:
有个Manager Center的管理界面,很漂亮,可以看到很多有用的数据。包括每个Map的请求次数等。这些在Memcached,Redis上只能看个大概。
简单的配置很方便,可以像JDK里的Map,List一样使用。
坑爹事情
配置各种找不到
有很多xml的配置方式没有写在文档上,要到代码里各种找。友情提示,可以到代码里的test目录下找到比较完整的配置:
https://github.com/hazelcast/hazelcast/blob/maintenance-3.x/hazelcast-spring/src/test/resources/com/hazelcast/spring/node-client-applicationContext-hazelcast.xml
有很多参数的配置没有写在文档上,要到代码里各种找。友情提示,在com.hazelcast.instance.GroupProperties 这个类里找到一些在文档上没有的配置参数。
默认的超时配置太长
很多超时配置都是上百秒的,试想现在的网站或者应用,有哪个可以忍受上百秒的超时。从另一个侧面也可以看出hazelcast的自己的信心不足,要靠超长时间的超时来保证运行的正确性。
即使配置了较短的超时时间,还是有可能会有各种出人意料的超时,认真研究过代码后,发现是有很多超时时间是在代码里写死的。。
版本之间不兼容
版本之间不兼容,不能滚动升级。这就意味着,当升级时,整个集群都要一块重启,这对很多网站来说,是不能忍受的。据说从3.1版本后会保证小版本的兼容性。
https://github.com/hazelcast/hazelcast/issues/14
hazelcast里代码一大问题就是把序列化方案和网络通讯混在一起了,导致各种升级兼容问题。每个消息包在解析时,都有可能因为类有改动而不兼容。
而且序列化方案还是那种要实现一个特定接口的。在Protobuf,Thrift,及各种基于反射的序列化方案这么流行的今天,很难想像会有这样难用的序列化方式。
一个结点出问题,影响整个集群
当集群里某个节点出故障时,比如OOM,CPU100%,没反应之后,集群里发到那个结点的操作就各种超时,各种不正常。这个可以算是hazelcast的一个致命的缺点。
我们线上的集群有30多个结点,随便一个有问题,都会导致整个集群有问题。另外,当集群里有一个应用下线/上线,都会引起数据的迁移,尽管迁移是自动的,但是也是一个不可控的风险。
我们开始时用的是hazelcast2.5.1,后来升级到3.1.3版本。升级后发现两个结点间经常会有网络流量超高的情况,最后发现是merge-policy的配置在3.0只能配置类的全名,而在2.5是可以配置一个简称的。然后在集群里有数据要迁移,进行Merge时,就会因为ClassNotFoundException而失败。而Hazelcast坑爹的地方在于它不断地重试,而且是无停顿地重试,从而导致两个结点之间网络流量超高,甚至超过了100Mbps。
hazelcast client很难用
首先,还是文档太少,很多配置根本没有提到,得自己到代码里去找。
另外,如果hazelcast server集群全部挂掉后,client居然不会自己重连(重试3次就放弃了)。现在的各种组件重启是很正常的事情,而hazelcast client居然不会自动重连,真心令人无语。更加扯蛋的是,比如map.get,如果没有连接上,会抛出一个RuntimeException,那么整个线程都退出了。
3.0版本和3.0.2版本之间的配置格式居然有很大的变化,很多时候,找个配置,得自己去看xml的xsd文件。。
结点之间Merge时,需要反序列化
这个我认为是代码太多导致的混乱。结点之间数据合并时,本来只要比较下数据的版本,时间等就可以了,但是在合并时却把对象反序化出来。如果在Server端没有对应的jar包,则会抛出ClassNotFoundException。
参考这里:
https://github.com/hazelcast/hazelcast/issues/1514
一些原理性的东东
Partition
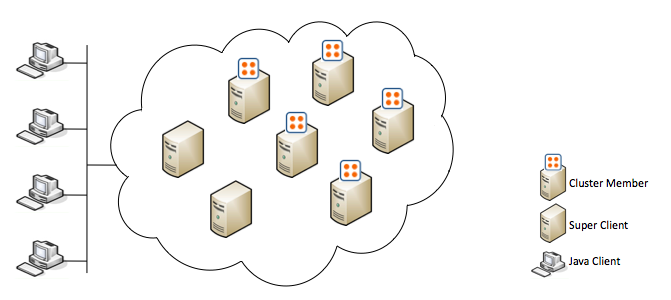
从原理上来说,hazelcast是默认有271个partition,这271个parition平均分布在集群里的结点中,因此集群里的数据分散在每个结点中。然后在进行操作时,先计算得到key所在的partiion,再进行操作。
详细请参考PartitionServiceImpl这个类的代码:
- public final int getPartitionId(Data key) {
- int hash = key.getPartitionHash();
- return (hash != Integer.MIN_VALUE) ? Math.abs(hash) % partitionCount : 0;
- }
NearCache的实现原理
hazelcast里有一个所谓的nearcache的东东,其实这个很简单,就是一个本地的二级缓存。在get的时候先到本地的nearcache里查找,如果没有计算hash,再到对应的结点中取数据,再放到nearcache里。
参考:
http://www.oschina.net/p/hazelcast
http://www.hazelcast.org/docs/3.1/manual/html-single/
示例代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
import com.hazelcast.config.Config;
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
import java.util.concurrent.ConcurrentMap;
public class DistributedMap {
public static void main(String[] args) {
Config config = new Config();
HazelcastInstance h = Hazelcast.newHazelcastInstance(config);
ConcurrentMap<String, String> map = h.getMap("my-distributed-map");
map.put("key", "value");
map.get("key");
//Concurrent Map methods
map.putIfAbsent("somekey", "somevalue");
map.replace("key", "value", "newvalue");
}
}
|