Lucene入门
Lucene的开发语言是Java,也是Java家族中最为出名的一个开源搜索引擎,在Java世界中已经是标准的全文检索程序,它提供了完整的查询引擎和索引引擎,没有中文分词引擎,需要自己去实现,因此用Lucene去做一个搜素引擎需要自己去架构.另外它不支持实时搜索,但linkedin和twitter有分别对Lucene改进的实时搜素. 其中Lucene有一个C++移植版本叫CLucene,CLucene因为使用C++编写,所以理论上要比lucene快. 在lucene的基础上衍生了需要全文检索引擎项目,后面会有介绍,目前lucene已经加入apache大家庭。
官方主页:http://lucene.apache.org/
经典学习资料下载:lucene
in action
CLucene官方主页:http://sourceforge.net/projects/clucene/
在了解lucene之前先让我们了解全文检索的基本结构:

全文检索主要分为:数据抓取,索引构建,数据查询及部分构成。数据的抓取要是是从文件系统,数据库,或从网络抓取及部分。索引文档的构建比较复杂,需要根据具体的文档内容,根据对应的分词分析,构建索引。
数据查询也是比较复杂的过程,首先需要根据查询关键词,根据相应的分析器切分词,去查询相应的索引,最后
将结果返回。
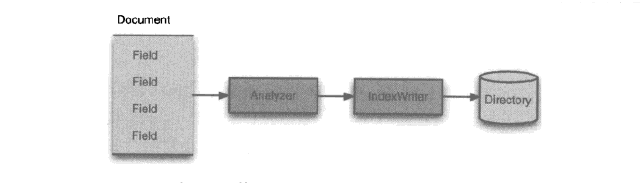
Lucene作为一个全文检索的类库仅仅提供底层的index documents建立索引 与searchindex搜索索引 两部分,也就是不能像google那样的可以部署直接使用的全文检索服务。如图所示:

lucene几个核心类:
IndexWriter,Directory,analyzer,document,field
Indexsearcher,Term,Query,TermQuery,TopDocs
a.
IndexWriter:写索引,负责索引文档的写入,复杂索引文件的写入,修改或新建,无查询功能。
Directory:描述了索引的缩放路径,是一个抽象类,有具体的子类实现对应的类型相应的路径。
Analyzer:分析器,对于文件在处理之前都要经过分析器处理,分析器负责提取文件中词汇单元,过滤掉无用信息,一切索引的构建必须经过分析器处理,拆分成具体的field。
Document:文档,实际存放数据的类,由field域构成。
Field:域,也就是实际文档构成部分。包含了实际索引的文本内容。
b.
Indexsearcher:索引查询类,复杂查询由IndexWriter写入的索引。
Term:term是搜索功能的基本单元与field类似,由域名,文本值构成,可以理解为经过分词器分出的最小词汇单元。
Query:lucene中的查询类,由许多子类构成:TermQuery,BooleanQuery,PhraseQuery,TermRangeQuery,FilterdQuery,SpanQuery 等。
TermQuery:lucene中最基本的查询类型,用来查询包含特定项的内容,例如查询包含“阿里巴巴” 的最的文档。
TopDocs:一个指向查询结果的指针,可以根据具体的docId指向具体的文档Document。
Lucene几个概念:
加权boost:,任何的操作内容都要业务上的重要性主次之分,加权复杂对索引进行重要性上的分类,可以根据查询频率或业务主次性进行加权。加权分索引构建或查询时加权两种。
索引优化optimize:索引优化实际上是对索引文件进行压缩操作减少查询过程中的磁盘空间与查询效率。索引优化会消耗cpu,io加大性能消耗,实际上是一种以性能消耗换取时间的策略。
其他:
需要注意的是lucene是线程不安全的,在做多线程并发操作时需要根据lucene提供的版本做线程并发操作。
Java应用实例:
package com.sw.lucene;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class JdbcUtil {
private static Connection conn = null;
private static final String URL = "数据库url";
private static final String JDBC_DRIVER = "com.mysql.jdbc.Driver";
private static final String USER_NAME = "root";
private static final String PASSWORD = "密码";
public static Connection getConnection() {
try {
Class.forName(JDBC_DRIVER);
conn = DriverManager.getConnection(URL, USER_NAME, PASSWORD);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
}
package com.sw.lucene;
public class SearchBean {
private String id;
private String title;
private String content;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
package com.sw.lucene;
import java.io.File;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.Field.TermVector;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.Searcher;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/**
* SearchLogic.java
* @version 1.0
* @createTime Lucene数据库检索
*/
public class ArticleUtil {
private static Connection conn = null;
private static Statement stmt = null;
private static ResultSet rs = null;
private String searchDir = "E:\\Test\\Index";
private static File indexFile = null;
private static Searcher searcher = null;
private static Analyzer analyzer = null;
/** 索引页面缓冲 */
private int maxBufferedDocs = 500;
/**
* 获取数据库数据
* @return ResultSet
* @throws Exception
*/
public List<SearchBean> getResult(String queryStr) throws Exception {
List<SearchBean> result = null;
conn = JdbcUtil.getConnection();
if(conn == null) {
throw new Exception("数据库连接失败!");
}
String sql = "select id, title as title, article_content as content , article_type_id as type from tblog_article";
try {
stmt = conn.createStatement();
rs = stmt.executeQuery(sql);
this.createIndex(rs); //给数据库创建索引,此处执行一次,不要每次运行都创建索引,以后数据有 更新可以后台调用更新索引
TopDocs topDocs = this.search(queryStr);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
result = this.addHits2List(scoreDocs);
} catch(Exception e) {
e.printStackTrace();
throw new Exception("数据库查询sql出错! sql : " + sql);
} finally {
if(rs != null) rs.close();
if(stmt != null) stmt.close();
if(conn != null) conn.close();
}
return result;
}
/**
* 为数据库检索数据创建索引
* @param rs
* @throws Exception
*/
private void createIndex(ResultSet rs) throws Exception {
Directory directory = null;
IndexWriter indexWriter = null;
try {
indexFile = new File(searchDir);
if(!indexFile.exists()) {
indexFile.mkdir();
}
directory = FSDirectory.open(indexFile);
analyzer = new StandardAnalyzer(Version.LUCENE_30);
indexWriter = new IndexWriter(directory, analyzer, true, IndexWriter.MaxFieldLength.UNLIMITED);
indexWriter.setMaxBufferedDocs(maxBufferedDocs);
Document doc = null;
while(rs.next()) {
doc = new Document();
Field id = new Field("id", String.valueOf(rs.getInt("id")), Field.Store.YES, Field.Index.NOT_ANALYZED, TermVector.NO);
Field title = new Field("title", rs.getString("title") == null ? "" : rs.getString("title"), Field.Store.YES,Field.Index.ANALYZED, TermVector.NO);
Field content = new Field("content", rs.getString("content") == null ? "" : rs.getString("content"), Field.Store.YES,Field.Index.ANALYZED, TermVector.NO);
doc.add(id);
doc.add(title);
doc.add(content);
indexWriter.addDocument(doc);
}
indexWriter.optimize();
indexWriter.close();
} catch(Exception e) {
e.printStackTrace();
}
}
/**
* 搜索索引
* @param queryStr
* @return
* @throws Exception
*/
private TopDocs search(String queryStr) throws Exception {
if(searcher == null) {
indexFile = new File(searchDir);
searcher = new IndexSearcher(FSDirectory.open(indexFile));
}
//searcher.setSimilarity(new IKSimilarity());
QueryParser parser = new QueryParser(Version.LUCENE_30,"content",new StandardAnalyzer(Version.LUCENE_30));
Query query = parser.parse(queryStr);
TopDocs topDocs = searcher.search(query, searcher.maxDoc());
return topDocs;
}
/**
* 返回结果并添加到List中
* @param scoreDocs
* @return
* @throws Exception
*/
private List<SearchBean> addHits2List(ScoreDoc[] scoreDocs ) throws Exception {
List<SearchBean> listBean = new ArrayList<SearchBean>();
SearchBean bean = null;
for(int i=0 ; i<scoreDocs.length; i++) {
int docId = scoreDocs[i].doc;
Document doc = searcher.doc(docId);
bean = new SearchBean();
bean.setId(doc.get("id"));
bean.setTitle(doc.get("title"));
bean.setContent(doc.get("content"));
listBean.add(bean);
}
return listBean;
}
public static void main(String[] args) {
ArticleUtil logic = new ArticleUtil();
try {
Long startTime = System.currentTimeMillis();
List<SearchBean> result = logic.getResult("java");
int i = 0;
for(SearchBean bean : result) {
if(i == 10)
break;
System.out.println("<a href='http://www.songwie.com/articlelist/"+bean.getId()+"'>"+ bean.getTitle() +"</a>" );
i++;
}
System.out.println("searchBean.result.size : " + result.size());
Long endTime = System.currentTimeMillis();
System.out.println("查询所花费的时间为:" + (endTime-startTime)/1000+" 秒");
} catch (Exception e) {
e.printStackTrace();
System.out.println(e.getMessage());
}
}
}
本例子是一个简单的从数据库中查询数据创建索引,并查询的例子。
本文中用到的分词器是标准分词器:analyzer = new StandardAnalyzer(Version.LUCENE_30);
对中文支持不是很好如果需要中文支持需要对应的中文分析器,例如ik,一个最早的全文检索的国内大牛写的中文分词库。再集成中文分析器的时候要注意中文分词器与lucene的版本兼容问题: